
Capacity in scrum can be calculated using the team’s past velocity data and developers’ availability in future iterations.
Use my template to calculate the capacity for a scrum team.
If you work in SCRUM, and even more so in SAFE as a Scrum Master – then you need to know the capacity of the teams before planning a Sprint or Program Increment. In this article, you will find how to calculate the capacity and a ready-to-download template in xls format. But first, learn why it’s important to organize your data in this way.
What is capacity?
Briefly explained it is an iteration capacity. It’s the amount of work a team can plan, measured by a pre-defined unit used in previous sprints.
Capacity is a tool to answer the question: how much can you do in this sprint?
Or: When will it be ready?
Or: Will you deliver the functionality by…?
The answers to the above questions in the form of iteration capacity – sprints are of course an estimate of the work that can be done in the future.
It is based on the team’s experience from previous sprints and the characteristics of the planned work.
A well-chosen capacity involves the ability to estimate accurately.
Work estimation is an indispensable part of planning and therefore one of the main events in both SCRUM and SAFE.
A related term to capacity is velocity – I wrote a detailed article about it here. The knowledge about velocity is important as it is one of the inputs to calculate the capacity, more on it later.
How to ensure that the estimate is correct?
The probability of a correct estimate of work is directly proportional to:
- The alignment of the developers in the team,
- Equal understanding of the unit of measure,
- Accuracy of the performed refinement
Estimation vs. developer alignment
A simple explanation of this relationship is, of course, one of the benefits of people in a team being in tune with each other – predictability.
When working with someone we want to be sure of the other person’s commitment. We want to be sure that he/she is competent to perform the planned tasks, that he/she will provide support if it is needed.
On the other hand, being aware that a person from the team is not involved, that he/she does not have the competencies or is just gaining them, or that he/she does not want to share knowledge is also a form of predictability and favors probable estimation – even though this is not necessarily the team we would like to co-create or build.
So the better we know each other, the better we estimate.
The stability of the team is crucial – frequent staff fluctuations preclude accurate planning and the capacity of the team can at best be guesswork – with the right approach calculated but still guesswork.
Therefore: Business! Invest in teams because their stability is the key to the predictability of your plans.
A common understanding of the unit of measure
The Story points will be taken as the unit of measurement, as I have not encountered a different one in my work.
I emphasize that my table assumes that the team uses an empirical approach to the story point.
This approach is characterized by comparing the size of tasks against each other in relation to similar backlog items performed in the past.
We need to forget about the time required to complete them.
Mixing empirical estimation with so-called man-days (working days per employee, MD for short), in my opinion, misses the point completely.
Teams that use the comparison e.g. 1SP=0,5MD=4h may as well not estimate in story points but instead, switch to estimation in
hours.
A common understanding of SP is like a common language we use to communicate effectively.
A good estimation is the result of teamwork on planning – discussion on how to implement business requirements.
A reflection of this is planning poker where the team discusses the complexity of tasks using a single scale. This discussion aims at bringing the unit of measurement, here 1SP, to a common denominator.
I took a deep dive into the story point subject in What is a story point in agile? – please read it for more details.
Accuracy of the performed refinement
The Product Owner explains the business requirements during the decomposition of the backlog elements (backlog refinement).
A fantastic situation is a refinement preceded by the work of the Product Owner with a UX designer. It gives developers a visualization of the requirements so that they are easier to understand and translate into software logic.
This relationship is intuitive – the better we know what to do, the better we know how.
The first capacity is sometimes taken out of a hat
Iterations that accompany team building are usually over or underestimated. This is due to the fact that one or several of the above-mentioned elements at the same time is weak. These aspects are definitely worth observing and working on.
I think that workshops are necessary at the beginning to help the team get to know each other and to work out a common system and perception of the complexity of the work they have to deal with.
How to calculate capacity – the method
We know each other, we have a common measure, and we know exactly what to do.
When the team says the above sentence and I believe it to be true, I have peace of mind about planning and can prepare capacity with confidence.
The inputs to the method are (in green in the table):
- Sprint length in days
- Number of developers in the team
- Absences of individual developers
- Average team velocity from previous sprints with the same composition
With the above data, we are able to calculate the percentage attrition of each planned sprint. Assuming, of course, that the team will be stable and its velocity will be similar to the average value of the previous sprints. All in all, it sounds simple right? Because it actually is very simple 🙂
Well, now some maths 😛
Fortunately in a spreadsheet.
Input data
We list each planned iteration for the Heroes team in columns.
It’s good to indicate how long the iteration lasts, how many team members there are, the average speed of each team, we also indicate all absences.
Finally, we prepare all the input data (in green in the table).
The product of the number of developers and the number of days in the sprint results in the total number of working days for the entire team, in the example below 40 – this will be our 100% attendance that is possible.

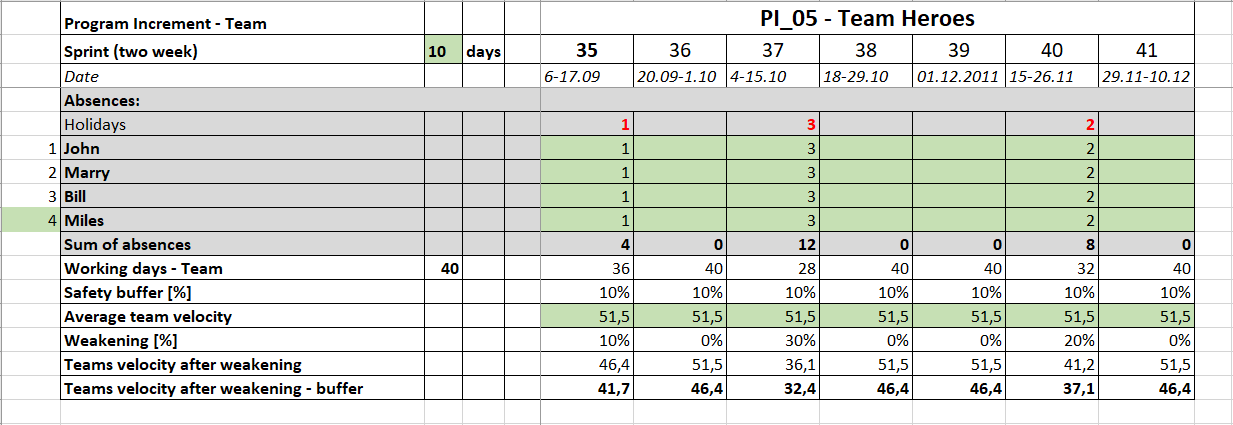
Absences
Bear in mind that this is not holiday planning but absences.
Every absence counts, whether it’s a holiday, a planned medical procedure.
Begin with listing all holidays that fall on each iteration.
This is an element that can affect additional absences so it’s worth showing it to the team at the start.
As long as the rule is that we don’t work on holidays – each developer inherits the holiday value:
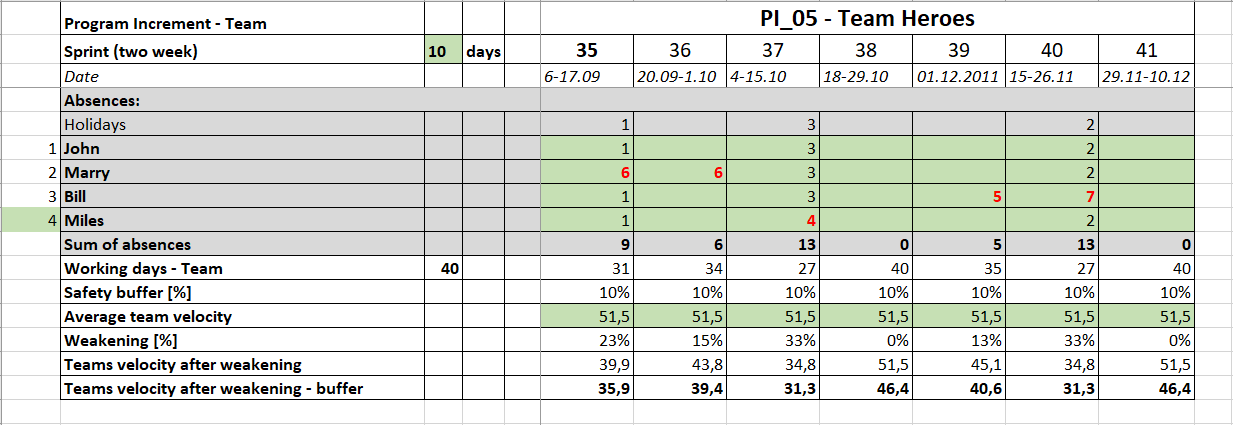
Secondly, collect information from developers when they plan their absences.
Thirdly, add these to absences due to public holidays.
In the example below, Marry plans 5 days holiday in sprints 35 and 36, Miles plans 1 day holiday in sprint 37 and Bill plans 5 days holiday in sprints 39 and 40:
Velocity impairment
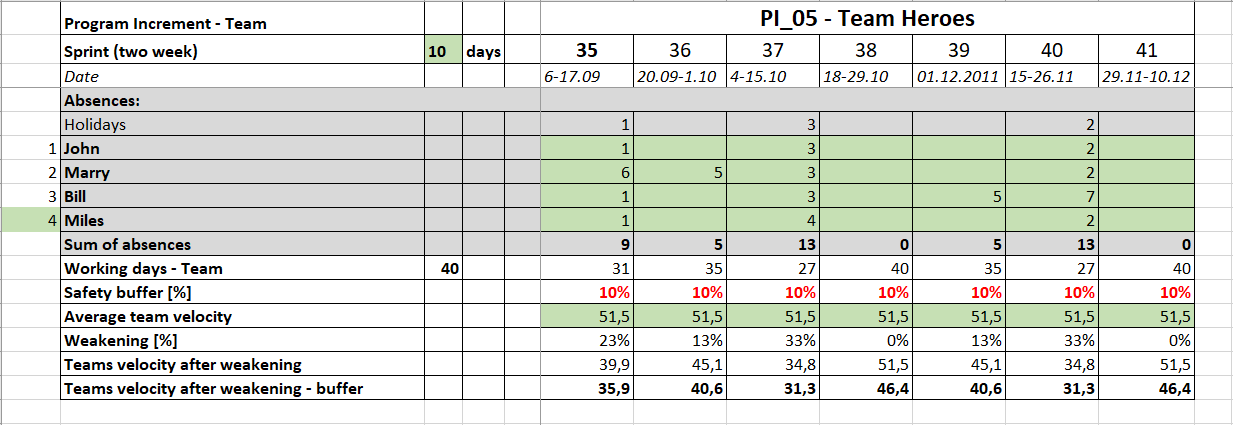
The quotient of the sum of all developers’ absences in a given sprint to the sum of all possible working days is the percentage Weakening for that sprint.
For example, in sprint 35 you have 9/40=0.23
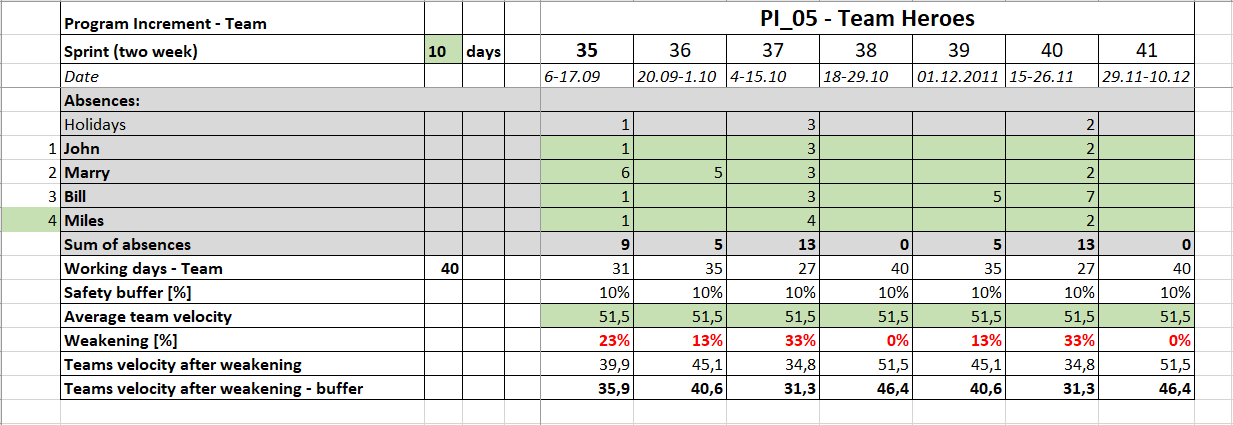
Velocity after weakening
I now reduce the average team velocity of the previous sprints by the weakening factor and I get the value of teams velocity after weakening, i.e. in the 35th sprint 51.5-(51.5*0.23)=39.9
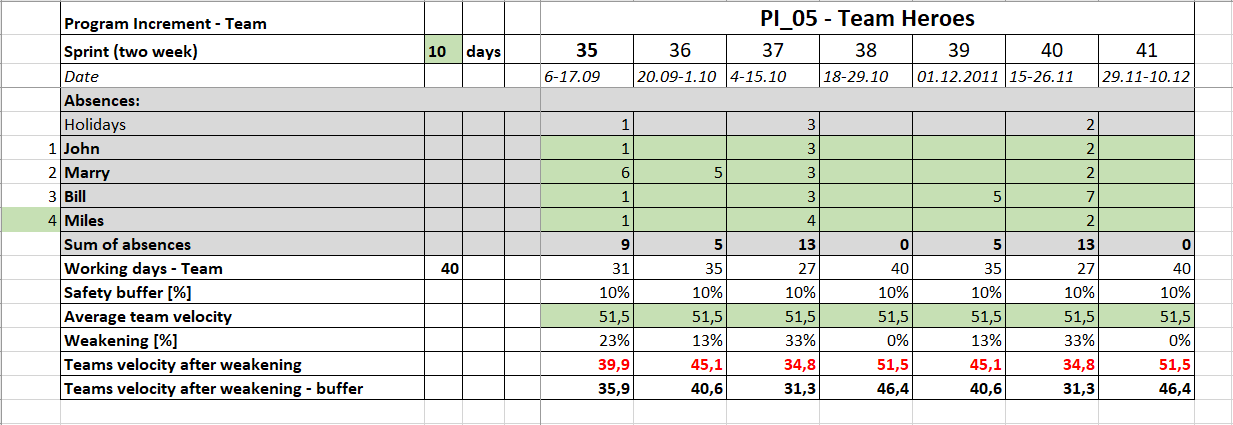
Safety buffer
This is a value that further reduces the speed to obtain the final capacity.
The Safety Buffer is discretionary and depends on team experience, planned dependencies, substitutability of competencies in the team. In this example I assume a value of 10%, this value may vary between sprints.
For a team experienced in estimation, with a stable list of persons, I would suggest giving a smaller buffer.
The more dependencies the larger the buffer should be.
If the team has no influence on the creation of the necessary elements e.g. produced by the system teams then the less they can commit to delivering the functionality.
One could ask: “At that time other work can be done so capacity is not affected?” Yes, it is affected, for example, the need to switch between threads stretches the time to deliver.
If you have a lack of substitutability in the team then the buffer must be larger.
In a cross-functional team, if the developer of a particular layer (e.g. front end) is absent, then often tasks cannot be finished.
If something is not finished then it is not finished.
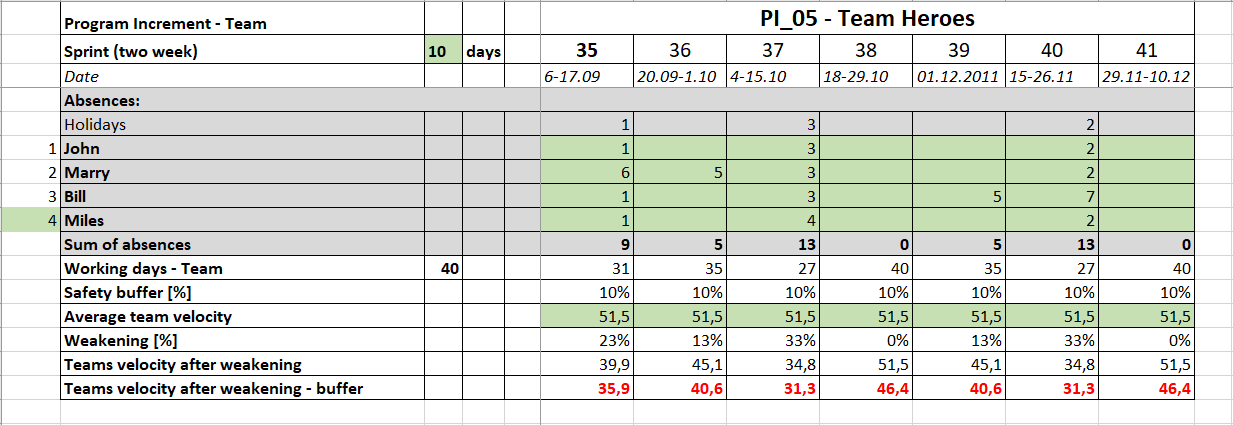
Sprint capacity
I now additionally reduce the velocity after the weakening by the Safety Buffer.
In sprint no. 35 the capacity is 39.9-(39.9*10%)=35.9
To get the final capacity result just round up the values, in this case, I would take 36 Story Points for 35 Sprint.
Adjusting on how to calculate the capacity
Question one
“Ok Michael, a nice way to calculate capacity but after all in a two-week sprint of 10 working days one whole day goes to ceremonies besides that we have refinement and some other meetings…”
No problem, luckily we have a spreadsheet with formulas so reduce the number of days in a sprint accordingly.
Note: the number of days in a sprint applies to all iterations covered by this table. Therefore, reduce accordingly taking into account only the
cyclic meetings like refinement, COP (communities of practice), etc., which happen every sprint.
When you have planned long meetings during the particular iteration, I suggest adjusting the buffer that applies to a single sprint.
Question two
“Okay Michael, but tell me how to do it if the team is separated from a larger one or a new person has joined – the composition is not the same as in previous sprints.”
Well, here we have a problem because there are unknowns of input data in the form of average speed from previous iterations and familiarity within team members.
In this case, for example, if a new member joins the team, you have to rely on their estimation. Before planning, you have to find a common denominator in understanding Story Points.
If there is no time for a workshop on task estimation then it could be based on a model, typical task, e.g. 3 SP.
A new person seeing the complexity of the task and its estimation will use it to estimate bigger and smaller tasks relatively.
It is important to analyze whether the new person will improve the workflow or cause a bottleneck.
In the second case, the speed may not increase much. For example, we add a back-end developer without adding anyone at the front-end and for testing.
Most probably the team will not be able to keep up with building the front-end. The only exception could be a junior developer of a given
layer, who needs attention or a person who will cross-functionally enrich the team
It is always worth reminding yourself before making a change that all the improvements you make except for bottlenecks – are illusory.
How to calculate capacity in a spreadsheet to download
In conclusion
The team expects a Scrum Master to help with making the right decision, and in cases such as capacity and velocity, it just calls for approaching the topic in an engineering way.
Based on the data that our beloved ticket control systems like JIRA can so beautifully serve us is a solid way to calculate capacity.








2 Responses
Great content! Keep up the good work!
Very good summary.